Contenu de l'article
- Présentation
- Installer le moteur de sécurité
- Installer la collection Apache2
- Installer un bouncer firewall
- Installer le bouncer PHP
- Notification vers Elasticsearch
- Liste blanche
- Débogage
- Liens
Présentation
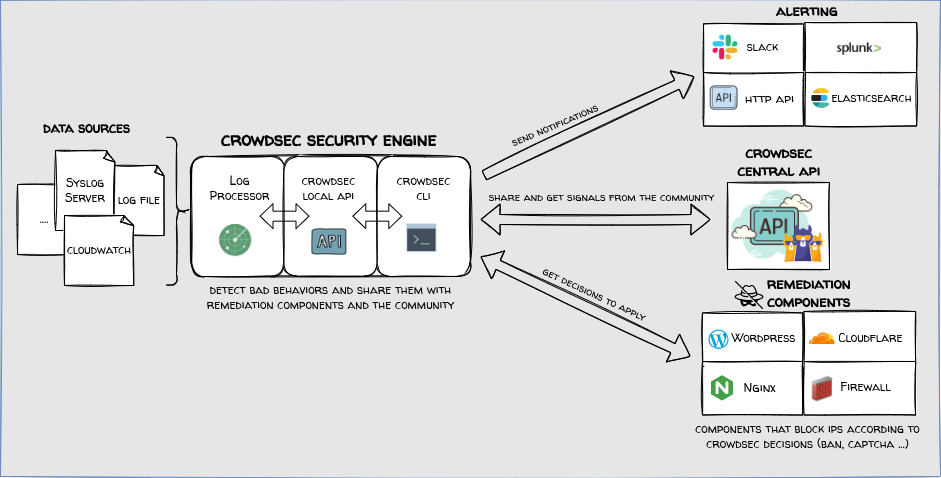
CrowdSec est un logiciel de sécurité informatique open-source conçu pour protéger les serveurs, services, conteneurs, ou encore les réseaux virtuels contre les attaques informatiques. L'idée derrière CrowdSec est assez innovante : il s'agit d'utiliser la puissance de la foule (d'où le nom "CrowdSec") pour détecter et bloquer les menaces de sécurité en temps réel. En gros, quand une attaque est détectée sur une machine, l'information est partagée anonymement avec la communauté CrowdSec. Cela permet à tous les utilisateurs du logiciel de bénéficier d'une protection renforcée, car ils peuvent bloquer l'attaquant sur leurs propres systèmes avant même d'être ciblés. Le fonctionnement de CrowdSec repose sur l'analyse des logs (journaux d'événements) pour détecter des comportements suspects. Si un comportement malveillant est identifié, l'adresse IP source de l'attaque est ensuite bannie, soit localement, soit à travers toute la communauté grâce à une base de données centralisée d'adresses IP malveillantes. C'est un peu comme un système immunitaire partagé où chaque nouvelle attaque renforce la défense de toute la communauté.
https://docs.crowdsec.net/docs/intro/
Les collections
Les collections sont des regroupements de configurations, comprenant des parsers, des scénarios et des postoverflows, destinés à un contexte ou une application spécifique. Une collection permet d'installer en une seule commande tous les éléments nécessaires pour protéger un service particulier ou répondre à un besoin de sécurité précis. Ci-dessous, quelques exemples de collections :
-
crowdsecurity/apache2 : Cette collection comprend des parsers pour les logs d'Apache, des scénarios pour détecter des attaques comme les injections SQL, les tentatives de force brute, et des postoverflows pour enrichir les données avec des informations géographiques.
-
crowdsecurity/ssh : Inclut des parsers pour les logs SSH, des scénarios pour détecter les tentatives de force brute et autres comportements malveillants spécifiques aux services SSH, et des postoverflows pour normaliser les événements.
-
crowdsecurity/linux : Une collection plus générale qui peut inclure des parsers pour différents types de logs de système, des scénarios pour détecter une variété de comportements malveillants sur un système Linux, et des postoverflows pour enrichir et normaliser les données.
Les parsers
Les parsers (ou analyseurs) sont des composants de CrowdSec qui traitent les logs en entrée pour les convertir en un format structuré que CrowdSec peut utiliser. Ils sont responsables de la lecture et de l'analyse des fichiers de logs provenant de différentes sources (comme Apache, Nginx, SSH, etc.) et de l'extraction des informations pertinentes (comme les adresses IP, les types de requêtes, les statuts HTTP, etc.).
Quelques exemple de parsers :
- Apache2 parser : Analyse les logs d'Apache pour extraire les informations nécessaires.
- Syslog parser : Analyse les logs de syslog pour en extraire les événements de sécurité pertinents.
Les scénarios
Les scénarios sont des ensembles de règles ou de modèles de comportement définis dans CrowdSec pour détecter des activités suspectes ou malveillantes. Chaque scénario décrit une série d'événements ou de conditions qui, lorsqu'elles sont rencontrées, déclenchent une alerte ou une action de défense. Les scénarios peuvent détecter des comportements comme les tentatives de force brute, les scans de ports, les injections SQL, etc.
Quelques exemples de scénarios :
- ssh-bf (SSH Brute Force) : Détecte les tentatives de force brute sur les services SSH.
- http-bad-user-agent : Détecte les requêtes HTTP utilisant des agents utilisateurs malveillants ou suspects.
- http-cve-2021-41773 : Détecte les tentatives d'exploitation d'une vulnérabilité spécifique dans Apache.
Les postoverflows
Les postoverflows sont des traitements supplémentaires appliqués après l'analyse initiale et la détection des scénarios. Ils permettent de réaliser des actions supplémentaires sur les événements détectés, comme la normalisation des données, l'agrégation des événements, l'ajout d'informations contextuelles, ou la suppression de faux positifs. Les postoverflows aident à affiner les détections et à améliorer la qualité des alertes générées.
Quelques exemples de postoverfows :
- Crowdsec-normalizer : Normalise les événements pour les rendre plus cohérents et faciles à analyser.
- Crowdsec-geoip-enricher : Ajoute des informations géographiques aux adresses IP détectées, comme le pays ou la ville d'origine.
- Http-logging : Enregistre les événements HTTP pour un examen ultérieur.
Exemple de Flux de Traitement
- Log d'Apache : Un fichier de log est généré par Apache HTTPd.
- Parser Apache : Le parser lit le fichier de log et extrait les informations nécessaires (IP, requête, statut, etc.).
- Scénario : Les données extraites sont passées à différents scénarios pour détecter des comportements malveillants (par exemple, tentatives de force brute).
- Postoverflow : Les événements détectés sont ensuite traités par des postoverflows pour ajouter des informations contextuelles ou affiner les résultats.
- Action : Si un comportement malveillant est confirmé, une action est déclenchée (comme bloquer l'IP).
Les bouncers
Les composants de remédiation (bouncers) sont chargés d'effectuer les actions liées aux décisions prises par le moteur de sécurité comme par exemple une action de blocage ou de demande de confirmation par Captcha. Les bouncers s'installent sur les machines devant appliquer les décisions et doivent donc pouvoir consulter régulièrement l'API du moteur de sécurité qui peut éventuellement se situer sur une autre machine. Sans bouncer, les décisions sont prises et loguées dans l'API du moteur de sécurité mais ne seront jamais appliquées. Il existe divers composants de remédiation disponibles adaptés aux différents contextes possibles.
Installer le moteur de sécurité
- Installer le dépôt Crowdsec. Le dépôt Crowdsec permet d'installer les dernières versions du moteur de sécurité et des composants de remédiation. Pour mettre en place le dépôt, lancer le script fourni avec la commande suivante :
# curl -s https://install.crowdsec.net | bash
- Installer le moteur de sécurité Crowdsec avec la commande suivante. Le moteur de sécurité est chargé d'analyser les logs pour détecter les menaces et d'enregistrer des décisions à suivre :
# dnf install crowdsec
L'application est alors enregistrée dans le répertoire /etc/crowdsec tandis que les données sont enregistrées dans le répertoire /lib/crowdsec/data
L'installation du moteur installe également quelques collections permettant la détection de menaces.
Le fichier Unit géré par systemd est le suivant : /usr/lib/systemd/system/crwdsec.service - Le service a besoin d'accéder au web notamment pour récupérer les adresses IP collectées par la communauté. Si Crowdsec doit utiliser un proxy, alors les informations se configurent au niveau de systemd. Pour éviter de modifier directement le fichier Unit de Crowdsec qui serait écrasé en cas de mise à jour, nous pouvons créer un fichier de surcharge avec la commande suivante. Ce fichier sera alors enregistré dans /etc/systemd/system/crowdsec.service.d :
# systemctl edit crowdsec.service
- Spécifier dans le fichier de surcharge les informations de proxy. Eviter la syntaxe "=http://" dans l'adresse du proxy car cela peut poser un problème de lancement du service sur certaines machines :
[Service]
Environment="http_proxy=your-proxy-server:port"
Environment="https_proxy=your-proxy-server:port" - Recharger la configuration de systemd :
# systemctl daemon-reload
- Lancer et activer Crowdsec au démarrage :
# systemctl start crowdsec
# systemctl enable crowdsec
Le fichier de configuration principal du moteur de sécurité est le suivant. Le service crowdsec doit être redémarré après chaque modification du fichier :
/etc/crowdsec/config.yaml
- Nous pouvons vérifier si des alertes ont déjà été émises et si des décisions ont déjà été prises avec les commandes suivantes :
# cscli alerts list
# cscli decisions list - Si nous voulons supprimer des décisions prises, nous pouvons utiliser les commandes suivantes :
# cscli decisions delete --ip <adresse_IP>
# cscli decisions delete --range <plage_IP>
# cscli decisions delete --id <ID_décision>
Installer la collection Apache2
Dans notre cas, nous allons sécuriser un reverse proxy Apache HTTPd.
- Lister les collections présentes :
# cscli collections list
- Normalement, la collection crowdsecurity/apache2 est déjà installée. Si nous devions l'installer, nos lancerions la commande suivante :
# cscli collections install crowdsecurity/apache2
- Mettre à jour l'ensemble des collections :
# cscli collections upgrade
- Nous pouvons éventuellement vérifier l'installation des éléments de collection avec les commandes suivantes :
# cscli parsers list
# cscli scenarios list
# cscli postoverflows list
Installer un bouncer firewall
Dans notre cas, nous installerons un bouncer permettant de bloquer le trafic au niveau d'un parefeu IPTables/NFTables (Firewalld - RHEL/Rocky Linux 9) suite à une décision de blocage prise par le moteur de sécurité. Le bouncer crée et gère un ensemble destiné aux adresses IP à bloquer et lui associe une règle de blocage.
Installation de cs-firewall-bouncer
- Installer le bouncer firewall iptables :
# dnf install crowdsec-firewall-bouncer-iptables
- Lancer et activer le bouncer au démarrage :
# systemctl start crowdsec-firewall-bouncer
# systemctl enable crowdsec-firewall-bouncer
Configuration
- Consulter et éventuellement ajuster la configuration du bouncer :
# vim /etc/crowdsec/bouncers/crowdsec-firewall-bouncer.yaml
RHEL 9 est compatible iptables mais utilise par défaut nftables. Nous réglons donc ce paramètre :mode: nftables
Etant donné que nous avons procédé à une installation automatique avec "dnf install", le bouncer s'est auto-enregistré auprès de l'API locale détectée sur le port 8080 en récupérant une clé, ce qui explique la configuration des paramètres suivants dans le fichier :
api_url: http://127.0.0.1:8080/
api_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx - Relancer le bouncer :
# systemctl restart crowdsec-firewall-bouncer
- La commande suivante permet de s'assurer du bon enregistrement du bouncer dans l'API :
# cscli bouncers list
- On peut également constater avec la commande suivante la présence de nombreuses IP à bloquer par nftable :
# nft list ruleset
Test de fonctionnement
Test 1
- Relever l'adresse IP qui fera le test d'accès au serveur et l'ajouter manuellement avec la commande suivante aux décisions de blocage de l'API :
# cscli decisions add --ip 1.2.3.4 --type ban --duration 4h - Vérifier avec la commande suivante que l'adresse IP a été ajoutée aux adresses bloquées par le bouncer :
# nft list ruleset | grep 1.2.3.4
- A partir de la machine possédant cette adresse IP, faire un test d'accès et constater l'échec de la connexion
Test 2
/!\ par défaut, Crowdsec ne bloque pas les adresses privées. Il faudra donc lancer nikto à partir d'une adresse publique pour pouvoir constater une prise de décision de Crowdsec.
Installer le bouncer PHP
https://www.crowdsec.net/blog/protect-php-websites
https://docs.crowdsec.net/u/bouncers/php
https://docs.crowdsec.net/u/bouncers/php-lib
https://blog.stephane-robert.info/docs/securiser/reseaux/crowdsec/
Notifications vers Elasticsearch
Crowdsec offre diverses options de notification. Les notifications peuvent être envoyées par email, Slack, webhook, et d'autres canaux. Parmi ces options, l'envoi des alertes vers Elasticsearch est particulièrement intéressant, car il permet de centraliser et d'analyser les données de sécurité en temps réel. En utilisant le plugin HTTP de Crowdsec, on peut configurer l'envoi des notifications vers un index Elasticsearch, en tirant ainsi parti des capacités de recherche et de visualisation avancées d'Elasticsearch associé à des outils comme Grafana ou Kibana. Notons que le plugin est déjà inclus dans l'installation de Crowdsec.
Configurer le plugin de notification HTTP
- Ouvrir le fichier profiles.yaml qui sert à déterminer au moyen de "profiles" quelles actions doivent être effectuées en cas de détections :
# vim /etc/crowdsec/profiles.yaml
- Activer les lignes suivantes afin que les alertes répondant aux critères du profil par défaut "default_ip_remediation" soient transmises au plugin de notification que l'on va nommer "http_elasticsearch" :
notifications:
# - http_default
- http_elasticsearch - Dans le fichier /etc/crowdsec/notifications/http.yaml, repérer le séparateur "---" de plugins de notification et ajouter après un nouveau plugin nommé http_elasticsearch en s'inspirant des paramètres suivants :
type: http
name: http_elasticsearch
log_level: debug # Options include: trace, debug, info, warn, error, off
format: |-
{{ range .}}
{"index": { "_index": "crowdsec"} }
{{.|toJson}}
{{ end }}
url: http://<IP_Elasticsearch>:9200/_bulk
method: POST
headers:
Content-Type: "application/json" - Si on veut vraiment ajouter des informations complémentaires relatives au serveur protégé, on peut s'en sortir en remplaçant le format utilisé par quelque chose comme ceci :
format: |-
{{ range .}}
{"index": { "_index": "crowdsec" }}
{"server": "my-server-name","data": {{ . | toJson }}}
{{ end }} - Relancer Crowdsec :
# systemctl restart crowdsec
Création d'un pipeline Elasticsearch
Nous souhaitons créer un pipeline d'ingestion par défaut c'est à dire une suite de traitements qui sera exécutée dans Elasticsearch avant l'indexation des données. Cela va nous permettre notamment d'ajouter des informations utiles comme des données de géolocalisation geoIP ainsi que de renormaliser certains formats de date non standard envoyés par le plugin HTTP de Crowdsec.
Dans Kibana, aller dans < Dev Tools > et lancer la requête suivante afin de créer le pipeline d'ingestion nommé crowdsec-pipeline qui corrigera les champs start_at et stop_at, ajoutera les informations de géolocalisation et ajoutera le champ @timestamp obligatoire pour utiliser des datastreams :
PUT _ingest/pipeline/crowdsec-pipeline
{
"description": "Pipeline pour extraire, renormaliser les dates et ajouter des informations de géolocalisation",
"processors": [
{
"script": {
"source": "String text = ctx.start_at;\nMatcher matcher = /(\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}:\\d{2})/.matcher(text);\nif (matcher.find()) {\n ctx.start_at_extracted = matcher.group(1);\n} else {\n ctx.start_at_extracted = null;\n}",
"description": "Extrait la date non standard du champ start_at"
}
},
{
"script": {
"source": "String text = ctx.stop_at;\nMatcher matcher = /(\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}:\\d{2})/.matcher(text);\nif (matcher.find()) {\n ctx.stop_at_extracted = matcher.group(1);\n} else {\n ctx.stop_at_extracted = null;\n}",
"description": "Extrait la date non standard du champ stop_at"
}
},
{
"date": {
"field": "start_at_extracted",
"formats": [
"yyyy-MM-dd HH:mm:ss"
],
"target_field": "start_at",
"timezone": "UTC",
"description": "Renormalise start_at avec la date extraite"
}
},
{
"date": {
"field": "stop_at_extracted",
"formats": [
"yyyy-MM-dd HH:mm:ss"
],
"target_field": "stop_at",
"timezone": "UTC",
"description": "Renormalise stop_at avec la date extraite"
}
},
{
"remove": {
"field": "start_at_extracted",
"description": "Supprime le champ intermédiaire start_at_extracted"
}
},
{
"remove": {
"field": "stop_at_extracted",
"description": "Supprime le champ intermédiaire stop_at_extracted"
}
},
{
"geoip": {
"field": "source.ip",
"target_field": "geoip_country",
"description": "Ajoute la géolocalisation par pays"
}
},
{
"geoip": {
"field": "source.ip",
"target_field": "geoip_city",
"description": "Ajoute la géolocalisation par ville"
}
},
{
"geoip": {
"field": "source.ip",
"target_field": "geoip_asn",
"database_file": "GeoLite2-ASN.mmdb",
"description": "Ajoute la géolocalisation par ASN"
}
},
{
"set": {
"field": "@timestamp",
"value": "{{created_at}}"
}
}
]
}
Il est également possible de créer, de consulter ou de modifier un pipeline d'ingestion en passant par la fonctionnalité < Stack Management / Ingest Pipelines > de l'interface graphique de Kibana.
Création d'un template Elasticsearch
Nous voulons maintenant créer un template pour configurer automatiquement les index qui seront utilisés pour enregistrer les données de Crowdsec.
- Dans Kibana, aller dans < Stack Management / Index Management / Index template > et cliquer sur "create template"
- Donner un nom au template, par exemple crowdsec-template, spécifier le pattern "crowdsec*" et activer le bouton "datastream". Si une demande de création d'index ou de datastream correspond au pattern, Elasticsearch sait qu'il doit utiliser ce template. L'avantage d'un datastream est qu'il facilite le cycle de vie des données en les enregistrant automatiquement dans des index numérotés masqués et qu'il s'utilise comme un simple index.
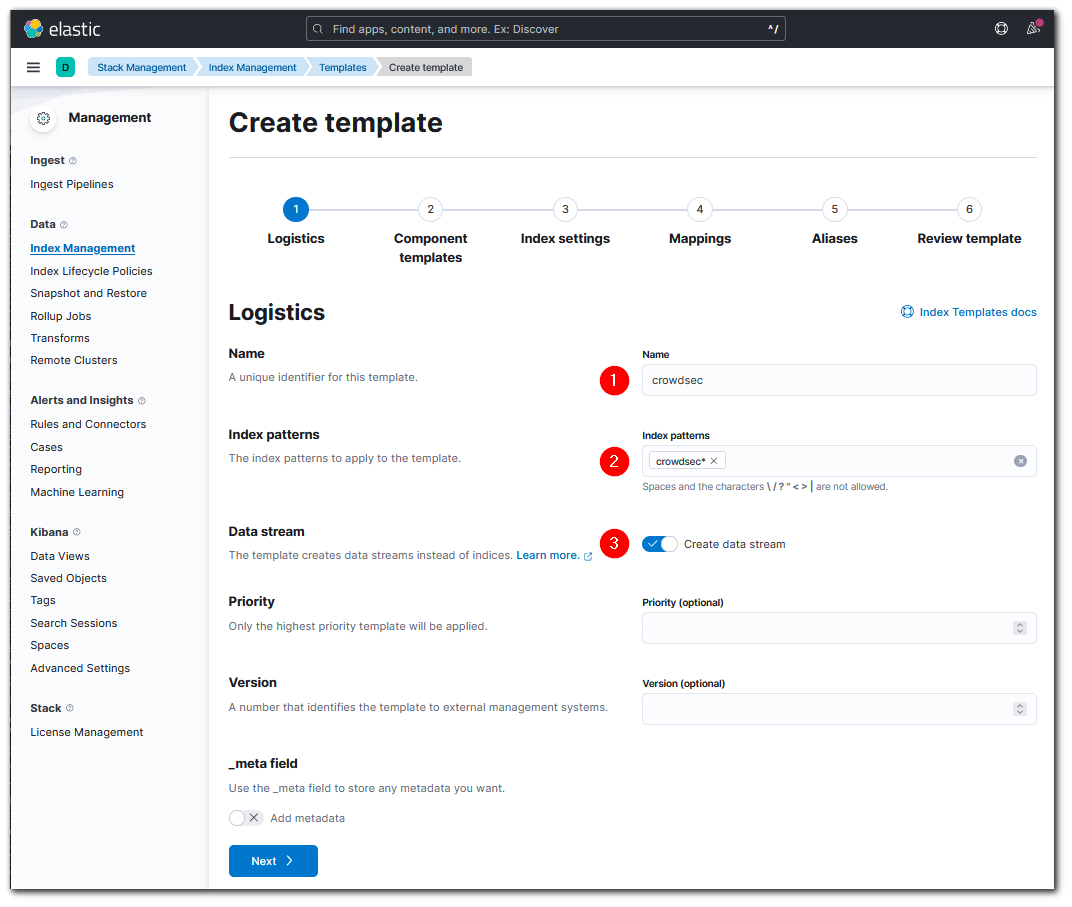
- Avancer jusqu'à l'étape 3 "Index Settings" en appuyant sur le bouton "Next" et ajouter la ligne suivante à la configuration pour que les nouveaux documents soient traités par le pipeline avant leur indexation :
"default_pipeline": "crowdsec-pipeline"
- S'il s'agit d'un environnement de test ou très peu critique, il peut être intéressant pour des questions de volumétrie de stockage de ne spécifier aucun réplicat de shard. Dans notre cas, nous ajoutons également les lignes suivantes à la configuration :
"number_of_shards": 2,
"number_of_replicas": 0 - Avancer jusqu'à l'étape de "Mappings" puis :
- copier le contenu de la partie "mapping" proposée sur le site de Crowdsec
- dans Kibana, cliquer à droite sur "Load JSON"
- coller dans la zone de texte proposée et valider
- éditer le champ events.timestamp et activer "Ignore malformed data" car sinon ce champ va nous bloquer.
Le template devrait maintenant disposer d'un mapping de base.
Attention : les modifications ne sont prises en compte que pour les nouveaux index/datastream basés sur ce template. Dans un environnement de test, il faudra donc peut-être recréer l'index/datastream utilisé s'il existe déjà. - Avancer jusqu'à la dernière étape pour enregistrer le template
- Etant donné que notre plugin de notification Crowdsec http_elasticsearch utilisera désormais un datastream et non plus directement un index, nous devons modifier son fichier de configuration /etc/crowdsec/notifications/http.yaml en remplaçant la ligne :
{"index": { "_index": "crowdsec"} }par la ligne :{"create": { "_index": "crowdsec"} }
Création d'un cycle de vie des données
Afin de gérer les ressources utilisées par les index de notre datastream, nous pouvons créer une politique de cycle de vie des index (ILM)
- Dans Kibana, aller dans < Stack Management / Index Lifecycle Policies > et créer une stratégie de cycle de vie nommée "crowdsec-lifecycle"
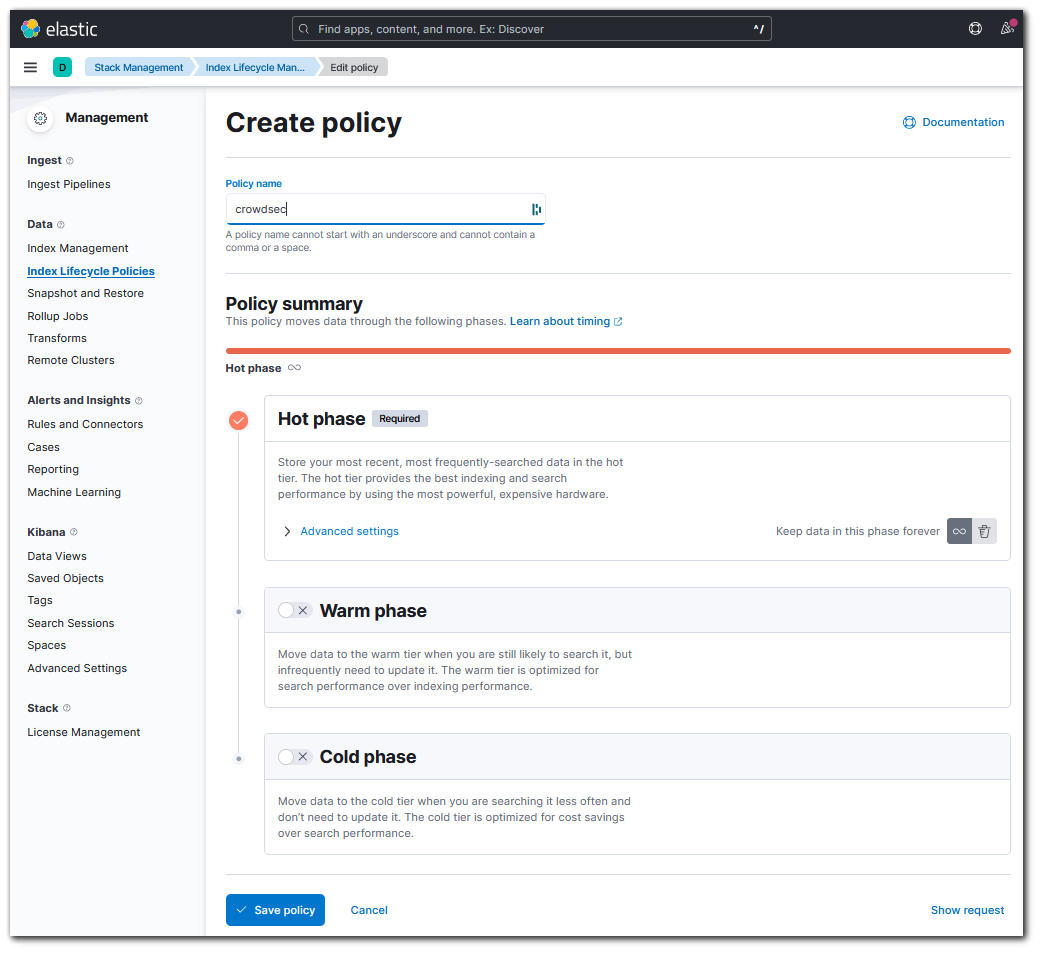
- Ajuster la politique de cycle de vie selon les besoins et enregistrer en cliquant sur "save policy".
Une politique de cycle de vie présente jusqu'à 3 phases qui vont de la plus active à la moins active. Il peut bien sûr y avoir plusieurs index dans une phase donnée et un index passe d'une phase à l'autre selon un critère d'ancienneté à configurer avec les 2 boutons de droite ("Keep data in this phase..."). Le roll-over de la phase "Hot" (première phase) spécifie quand l'index en cours d'écriture doit être renouvelé en fonction de critères d'âge et/ou de taille. - Associer la politique de cycle de vie en complétant l'étape 3 "Index Settings" vue précédemment avec les lignes suivantes. Pour "name", on spécifie le nom de la politique créée et pour "rollover_alias", le nom du datastream concerné :
{ "index": { "lifecycle": { "name": "crowdsec-lifecycle", "rollover_alias": "crowdsec" }, "default_pipeline": "crowdsec-pipeline", "number_of_shards": "2", "number_of_replicas": "0" } } - Par la suite, vérifier la progression du cycle de vie du datastream avec la requête suivante :
GET crowdsec-*/_ilm/explain
Tester les notifications
- Tester le plugin de notification avec la commande suivante. Attention, ce test s'applique à n'importe quel plugin de notification même s'il n'est pas activé et ne valide pas ce qui déclenche la notification (chaîne de traitement : log => parser => scenario => profile => alert => decision => notification) :
# cscli notifications test http_elasticsearch
- Constater avec Kibana la présence d'un index nommé "crowdsec" puis dans la rubrique "Discover", créer une dataview pour l'index et consulter le document enregistré lors du test.
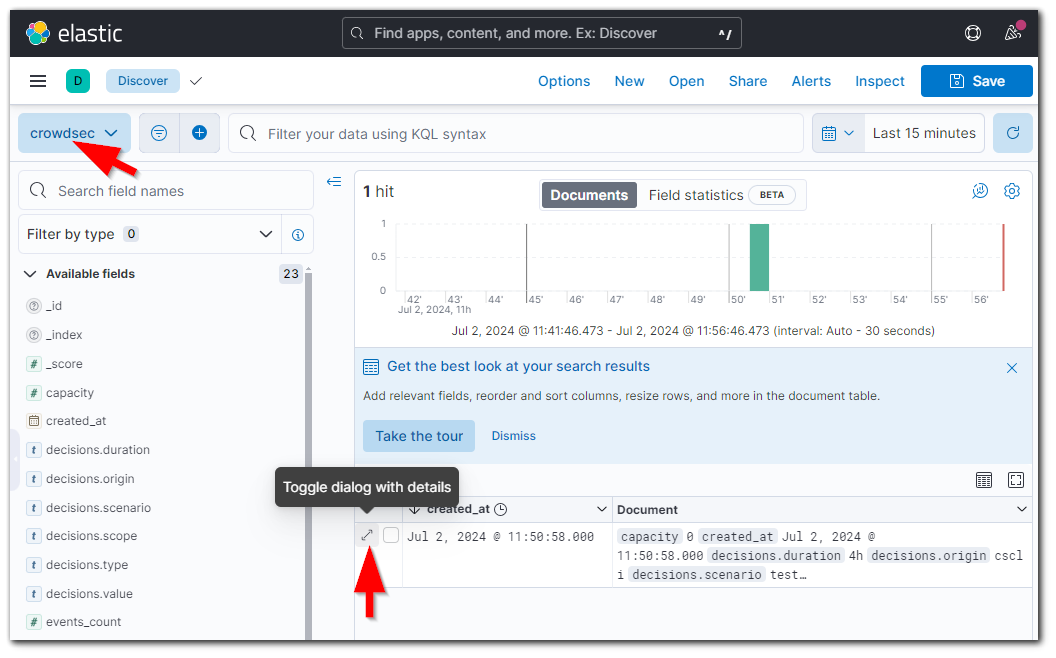
- Il est possible de valider le fonctionnement du profil qui déclenche la notification et la décision en réinjectant une alerte passée. Pour cela, lister les alertes et lancer l'une des commandes suivantes :
# cscli alerts list
On obtiendra alors des informations de débogage sur l'exécution des tâches déclenchées.
# cscli notifications reinject <alert_id>
# cscli notifications reinject <alert_id> -a '{"remediation": false,"scenario":"notification/test"}'
# cscli notifications reinject <alert_id> -a '{"remediation": true,"scenario":"notification/test"}'
Liste blanche
Dans certains cas, nous ne souhaitons pas bloquer certaines IP. Par exemple si une entreprise utilise un proxy ou une adresse translatée pour accéder au serveur protégé par Crowdsec, nous ne voulons peut-être pas bloquer la totalité des utilisateurs à la première requête douteuse. Nous pouvons alors décider de mettre cette adresse IP en liste blanche.
Crowdsec permet de créer des listes blanches au niveau des parsers ou au niveau des postoverflows. Contrairement à une liste blanche au niveau Parsers, le traitement d'une liste blanche en PostOverFlows génèrera des logs et sera effectué après une détection de scenario donc beaucoup moins souvent.
Pour créer une liste blanche d'adresses IP en postoverflows :
- Créer un fichier yaml dans le répertoire des traitements PostOverFlows :
# mkdir -p /etc/crowdsec/postoverflows/s01-whitelist
# vim/etc/crowdsec/postoverflows/s01-whitelist/mywhitelists.yaml - Configurer le fichier en s'inspirant du contenu suivant :
name: crowdsecurity/my-whitelist
description: "pas de bannissement du proxy"
whitelist:
reason: "ne pas bloquer le proxy"
ip:
- "x.x.x.x" - Redémarrer Crowdsec et vérifier les journaux :
# systemctl restart crowdsec
# journalctl -u crowdsec -f - Dans la durée, vérifier dans la liste des décisions et dans le log Crowdsec que l'adresse IP whitelistée n'est plus bloquée :
# cscli decisions list
# tail -f /var/log/crowdsec.logtime="2024-07-01T17:50:06+02:00" level=info msg="Ban for xxx.xxx.xxx.xxx whitelisted, reason [ne pas bloquer le proxy]" id=muddy-flower name=crowdsecurity/my-whitelist stage=s01-whitelist
time="2024-07-01T17:50:06+02:00" level=info msg="Ip xxx.xxx.xxx.xxx performed 'crowdsecurity/http-probing' (11 events over 352.789664ms) at 2024-07-01 15:50:06.733775437 +0000 UTC"
time="2024-07-01T17:50:06+02:00" level=info msg="[Ip xxx.xxx.xxx.xxx performed 'crowdsecurity/http-probing' (11 events over 352.789664ms) at 2024-07-01 15:50:06.733775437 +0000 UTC] is whitelisted, skip."
Débogage
Technique de débogage suivie pour résoudre un problème rencontré.
Description du problème
- Tout est en place, crowdsec, le plugin HTTP pour envoyer les alertes vers un datastream Elasticsearch et les tests avec les commandes "cscli notifications test" et "cscli notifications reinject ..." fonctionnent parfaitement. On peut lire les documents indexés dans Kibana / Discover
- Un test réel et complet généré par l'outil de scan de vulnérabilité Nikto déclenche bien des scenarios, alertes et décisions mais aucun document n'est créé dans Elasticsearch
Recherche du problème
- Activation du mode debug ("debug: true") dans le profile par défaut du fichier /etc/crowdsec/profiles.yaml + redémarrage du service crowdsec
- Test de scan avec Nikto
- Lecture du fichier /var/log/crowdsec.log , en particulier les ligne "debug"
- Identification de la ligne où le POST vers Elasticsearch est effectué ainsi que du retour d'erreur d'Elasticsearch. Nous disposons donc de la requête réellement effectuée et du message d'erreur du serveur Elasticsearch
- Le message d'erreur évoque un problème de parsing de date :
time="2024-07-04T12:14:43+02:00" level=debug msg="got response {\"took\":0,\"ingest_took\":0,\"errors\":true,\"items\":[{\"create\":{\"_index\":\"crowdsec\",\"_id\":null,\"status\":400,\"error\":{\"type\":\"illegal_argument_exception\",\"reason\":\"unable to parse date [null]\",\"caused_by\":{\"type\":\"illegal_argument_exception\",\"reason\":\"cannot parse empty date\"}}}}]} - Extraction de la partie requêteet collage dans notepad puis remplacement de \" par " puis encore de \\ par \
- Collage du bloc dans le meilleur viewer online de données JSON (même malformées) trouvé jusqu'ici à savoir http://json.parser.online.fr. Paiement de 10€ en soutien car ce parser est quand même super cool comparé à d'autres :-D
- Pas de problème particulier détecté dans le viewer online
- Copie du bloc notepad dans l'outil Dev Tools de Kibana afin de rejouer cette requête. Attention, il faut écrire le corps de la requête sur 2 lignes et non pas sous forme arborescente : une ligne {"create": { "_index": "crowdsec"} } et une autre pour tout le reste
- L'exécution de la requête retourne exactement la même erreur que dans le log crowdsec. On est donc maintenant en bonne voie pour faire du test/erreur et trouver le problème.
- Passage de tous les processors du pipeline d'ingestion en mode "ignore failure" sauf pour celui du @timestamp (champ obligatoire avec des datastream)
- Suppression progressive de parties de la requête jusqu'à ce que l'erreur change.
- Au bout de plusieurs coupes, Elasticsearch signale qu'il y a un problème de champ @timestamp. En effet, on initialisait de champ avec le champ "created_at" qui est tout le temps présent avec les commandes de test "cscli notifications test/reinject" mais pas lors d'un véritable test
- Initialisation de @timestamp avec la valeur toujours disponible {{_ingest.timestamp}}
- => la requête complète fonctionne désormais
Résolution
- Passage de tous les processors du pipeline d'ingestion en mode "ignore failure" sauf pour celui du @timestamp (champ obligatoire avec des datastreams)
- Initialisation de @timestamp avec la valeur toujours disponible {{_ingest.timestamp}} plutôt qu'avec {{created_at}}
- Dans Kibana, recréer un dataview qui se base non plus sur "created_at" mais sur @timestamp
Liens
- https://docs.crowdsec.net/docs/getting_started/install_crowdsec/
- ! https://blog.skwal.net/installation-de-crowdsec/
- https://www.crowdsec.net/blog/protect-php-websites
- https://www.it-connect.fr/comment-proteger-son-serveur-linux-des-attaques-avec-crowdsec/
- https://rdr-it.io/crowdsec-securiser-reseau-serveurs-web-installation-configuration/
- ! https://aymeric-cucherousset.fr/installer-crowdsec-sur-apache2-debian-11/
- https://rdr-it.io/crowdsec-envoyer-logs-elasticsearch-elk/
- https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-index-lifecycle-management.html#ilm-gs-apply-policy
- https://www.elastic.co/guide/en/elasticsearch/reference/8.4/data-streams.html
- https://docs.crowdsec.net/u/bouncers/firewall/
- https://docs.crowdsec.net/docs/next/profiles/intro